
Ghidra는 두 개의 서로 다른 바이너리의 연산자를 표시해주고 통합하는 기능이 존재합니다. 이번에는 Diff View를 이용하여 바이너리의 차이점을 쉽게 보는 방법을 알아봅시다.
Program Difference
Ghidra는 서로 다른 바이너리의 연산자를 표시하고 연산자를 통합하는 Program Difference가 존재합니다.
git diff 와 git merge 명령어를 합친 것과 비슷하다고 합니다.
이번 글에는 단순히 바이너리의 차이점을 표시하는 방법에 대해서 알아봅시다.
Code
두가지의 예시 코드가 있습니다.
첫번째 코드는 1~9 까지 출력하는 코드고(hello), 두번째 코드는 5~9 까지 출력하는 코드(hello-update)입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main(void){
int num = 10;
int i;
for(i=1;i<num;i++){
printf("current number is %d \n", i);
}
return 0;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
int main(void){
int num = 10;
int i;
for(i=5;i<num;i++){
printf("current number is %d \n", i);
}
return 0;
}
Diff View
Step1. Auto Analsys Setting
Ghidra에서 분석할 바이너리(hello-update)를 먼저 기드라로 임포트하여 아래와 같이 analyze now에서 yes를 누릅니다.
빨간색으로 표시된 Aggressive Instruction Finder(Prototype), Condense Filler Bytes(Prototype) 을 체크하여 저장합니다.
Step2. Program Differences
Ghidra에서 분석할 바이너리(hello) 연다음에 tools > Program Differences… 클릭합니다. 
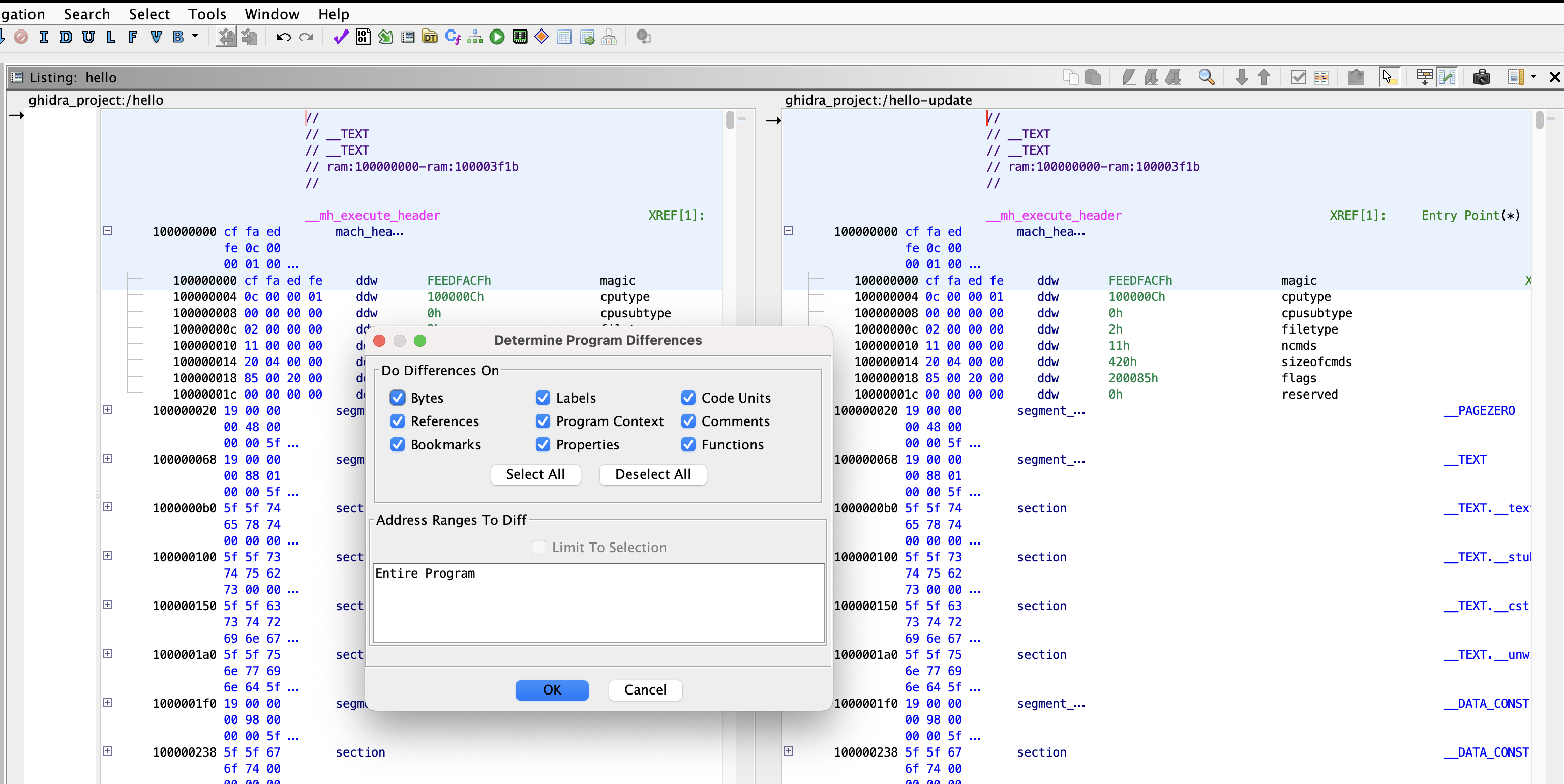
Step3. Determine Program Differences Setting
Determine Program Differences에서 설정이 존재하고 OK를 누릅니다.
Bytes : 다른 바이트 열을 가진 코드 유닛을 검출
Labels : 라벨이 다른 코드 유닛을 검출, 아래와 같은 경우는 다른것으로 간주함
→ 코드 유닛에 많은 라벨이 붙어 있는경우
→ 프라이머리 라벨이 다른 경우
→ 같은 라벨명이지만 범위가 다른 경우
→ 같은 라벨명이지만 소스가 다를 경우Code Units : 코드 유닛의 차이를 검출함, 코드 유닛 내의 명령이나 명령어가 다르면 연산자로 간주함
→ 명령이 다른 경우
→ 한쪽이 데이터인 경우
→ 코드 유닛에서 정의된 데이터 형이 다른 경우References : 참조가 다른 코드 유닛을 탐지함 아래의 경우 다른것으로 간주함
→ 한 쪽밖에 참조가 없는 경우
→ 참조처의 주소가 다른 경우
→ 같은 오퍼랜드 니모닉을 참조하지 않을 경우
→ 참조 타입(Memory, Stack, External)이 다른 경우- Program Context : 프로그램의 컨텍스트의 레지스터의 값이 다른 코드 유닛을 검출함, 레지스터가 정의되어 있지 않은 경우 프로그램 컨텍스트는 비활성화 됨
- Comments : 각 명령어가 다른 코드 유닛을 검출함
- Bookmarks : 북마크가 다른 코드 유닛을 검출함
- Functions : 함수가 다른 코드 유닛을 검출함, 아래와 같은 경우
→ 한 쪽밖에 존재하지 않는 경우
→ 함수의 명령어가 다른경우
→ 함수 내의 주소가 다른 경우
→ 함수의 서명(함수명, 반환값, 인수)이 다른 경우
→ 로컬 변수의 이름, 데이터형, 사이즈, 오프셋, 스택 오프셋이 다른경우
→ 스택 오프셋, 스택 사이즈가 다른 경우
Step4. Diff View
달라진 부분이 Listing창에서 주황색으로 표기됩니다.
0x1 -> 0x5로 변수 값이 바뀐 것을 알 수 있습니다.
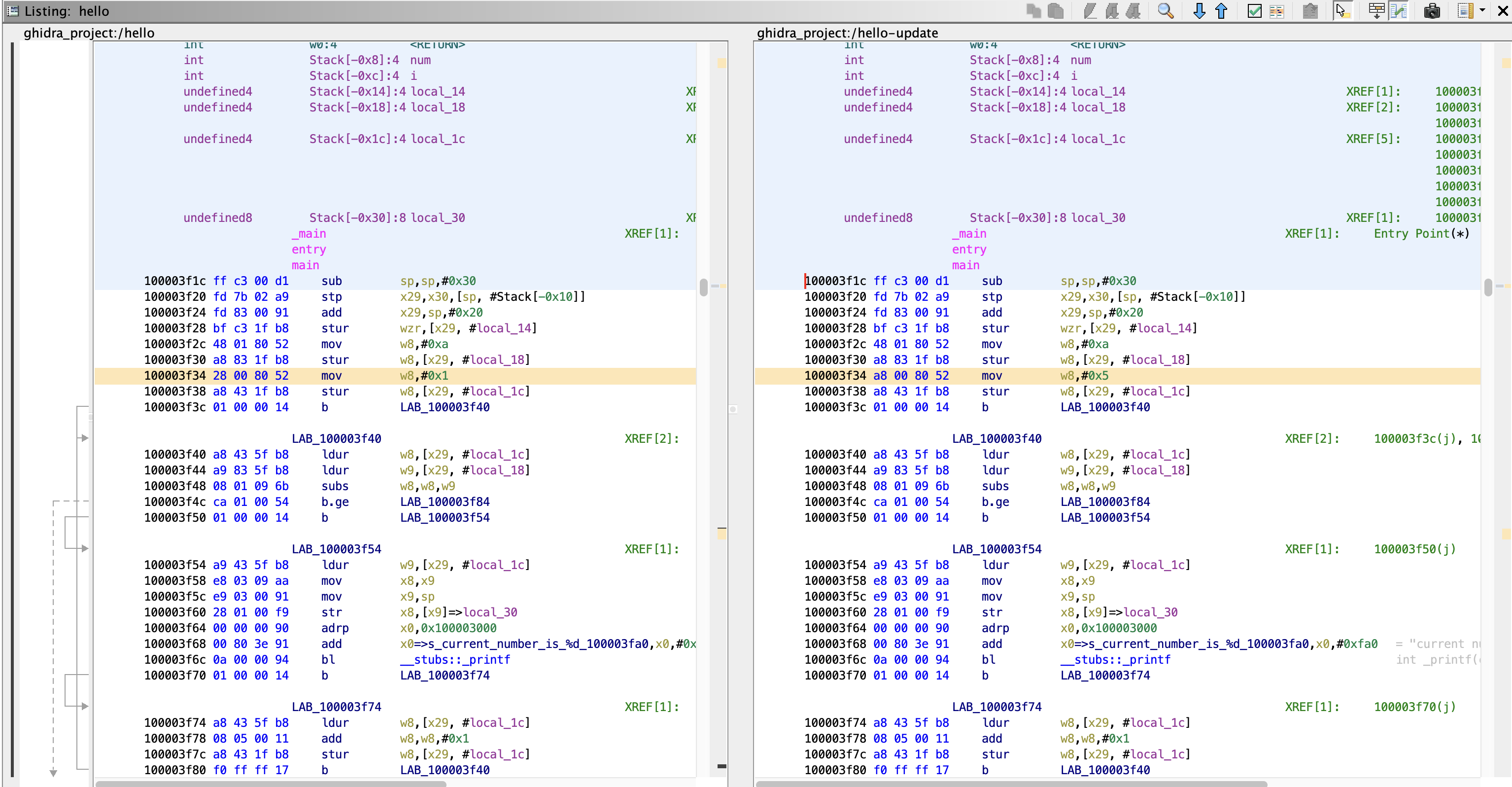
Listing에 표시되는 내용 밖에 비교할 수 없습니다.
디컴파일 결과는 비교할 수 없다는 소리!