워게임 문제를 풀다가 문자열을 검증 로직 우회와 관련한 재미있는 트릭이 있어 글을 남깁니다.
What is Unicode
유니코드(Unicode)는 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 __국제 표준 문자 인코딩 시스템__입니다.
Unicode의 주요 특징
- 범위 : 0~0x10FFFF 까지의 16진수 범위를 가지고 있습니다.
- 다국어 지원 : 유니코드는 세계의 다양한 언어를 포함
- 코드 포인트 : 유니코드에서 각 문자는 고유한 코드 포인트를 가지며, 16진수로 표현됩니다. -> ‘A’ -> U+0041
- 정규화 : 동일한 문자를 다른 여러 형태로 표현할 수 있는 문제를 해결(문자의 조합, 분해, 결합 표시마크등)
- 문자 조합과 분해 : 유니코드는 문자의 조합성을 고려하여 여러 개의 코드 포인트를 조합하여 문자를 표현할 수 있음
String compare bypass?
신기하게 Kelvin Sign 코드는 Decomposition을 하면 대문자 “K”가 되고 Lowercase Character를 하면 소문자 “k”가 됩니다.
실제로 그렇게 되는지 알아봅시다.
1
2
3
4
import unicodedata
kelvin_sign = "\u212A"
decomposition = unicodedata.decomposition(kelvin_sign)
print(decomposition) # 004B
결과가 004B가 나왔습니다. 004B는 유니코드에서 대문자 “K”를 말합니다.
1
2
3
4
5
6
7
kelvin_sign = "\u212A".lower()
comparison_char = "k"
if kelvin_sign == comparison_char:
print("same") -> 출력
else:
print("different")
신기하게 Lowercase Character 을 하면 006B 소문자 “k” 가 됩니다.
Trick
만약에 어떤 문자열을 검증하고 있고(대문자…) 내부적인 로직에서 lowercase() 할 경우 우회할 수 있습니다.
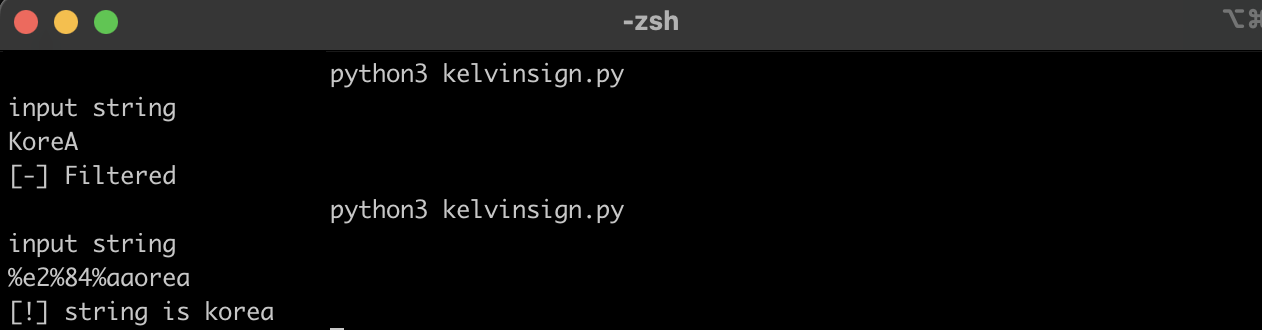
제가 만든 예시는 사용자의 인풋값을 upper()를 하여 KOREA인지 비교를 합니다. KOREA이면 필터링 문구가 나오게 하고, lower()한게 korea 나오게 하면 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
import urllib.parse
input_string = input("input string\n").encode('utf-8')
decoded_string = urllib.parse.unquote(input_string)
filtering_string = "KOREA"
if(filtering_string == decoded_string.upper()):
print("[-] Filtered")
elif(decoded_string.lower() == "korea"):
print("[!] string is korea")
else:
print("[-] incorrect string")
%e2%84%aa -> Kelvin Sign 입니다. 이것을 lower()하면 U+006B -> “k” 가되고 문자는 korea가 됩니다.